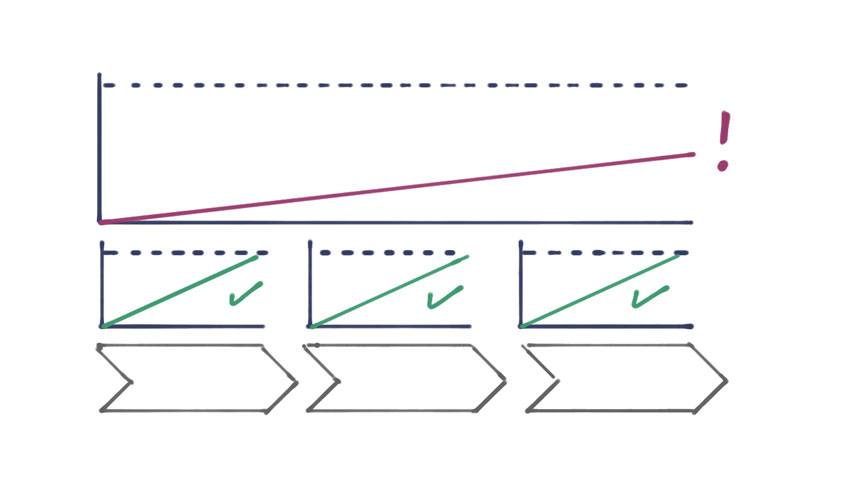
Three factors that slow down business processes
In the past few months your company spent a lot of time and effort into optimising their internal processes. Jobs and the separate process steps were scanned closely for potential weaknesses, and improved where possible. In the end all identified weak spots were addressed – and yet, the actual lead time was way behind the set target.
We have already described options for process optimization and continuous improvement in previous releases and know that if individual process steps are analysed and enhanced, the overall processes can be accelerated considerably. But often the real reasons why they are too slow go unnoticed as they are hidden in the interfaces between process steps.
Factor 1: Loops
In most cases delay is caused by the necessity to do rework whenever you have to loop back to a previous process step already completed. Just as there are different root causes for such rework, there are different approaches to identify and remove it.
Whenever rework is necessary to correct a mistake, this creates an unnecessary process loop. Process analysis, statistical data about errors or faulty products are useful tools to find out what flaws trigger the loop. The best way to address this problem is, obviously, to improve the workflow in a way that it runs smoothly. Alternatively, recognising errors as soon as possible minimises the waste of time due to rework.
Often, particularly in administrative processes, loops are the result of missing bits of information. Any query about earlier stages of a process costs time, especially so if the person responsible for the issue is not available. A systematic record of queries or direct interviews with relevant process participants can help identify possible weaknesses. Once the problem has been pinpointed, the interfaces between the respective process steps have to be adjusted I a way that all relevant information is being passed on, thus making further inquiries unnecessary.
Factor 2: Missing input
Just as loops caused by further inquiries waste time, so does information not gathered in time slow down business processes. The timing of when this specific input is being provided is particularly relevant in complex processes with two (or more) sub-processes.
In principle, there are two approaches to remedy such problems concerning interfaces. One straightforward fix is a Kanban system, so that the entire and complete input necessary for a certain process step is available when needed. Whenever the flow of goods and information has to be actively regulated, this method should be chosen. If, however, active input management is difficult to realise, it is advisable to work with a check list. In this way you can make sure in advance if all necessary input parameters are at hand before you start a process.
Factor 3: Idle time
In most cases it is idle time in the form of waiting that slows down processes. Whenever you do not directly move on to the next process step but keep your goods or data on hold, you are stuck in idle time.
To identify such periods of unproductive waiting, you have to scan critically the flow of goods and data within a process. Once you have found in the process chain the bottlenecks responsible for regularly creating idle time lost with waiting, you need to adjust the respective interfaces, either by a Kanban system or by implementing an early warning system preparing for the next process step.
As has been shown in these three instances slackening the processing pace, the process lead time is not only determined by single process steps, but, to a considerable degree, by their different interfaces and the flow of goods and information. This means that, in terms of process optimisation, these issues should be examined just as closely as the process activities themselves.